
探秘 Kubernetes 核心组件架构:云原生世界的精密交响乐团
在云原生的宏大舞台上,Kubernetes 无疑是那颗最耀眼的明星。它以一套精妙绝伦的核心组件架构,将集群中的资源调度与管理玩得风生水起,为现代应用的部署与运行保驾护航。今天,就让我们一起深入这个充满魅力的世界,瞧瞧这些核心组件到底是如何各司其职,共同奏响云原生的华丽乐章。
一、Kubernetes 架构全景概览
想象一下,Kubernetes 集群如同一个庞大且有序的工厂,每个组件都是这个工厂中不可或缺的部门,各自承担着独特而关键的职责。在这个工厂里,一切都围绕着资源的高效利用与应用的稳定运行展开。而要理解这个工厂的运作机制,我们得先从它的架构图入手。
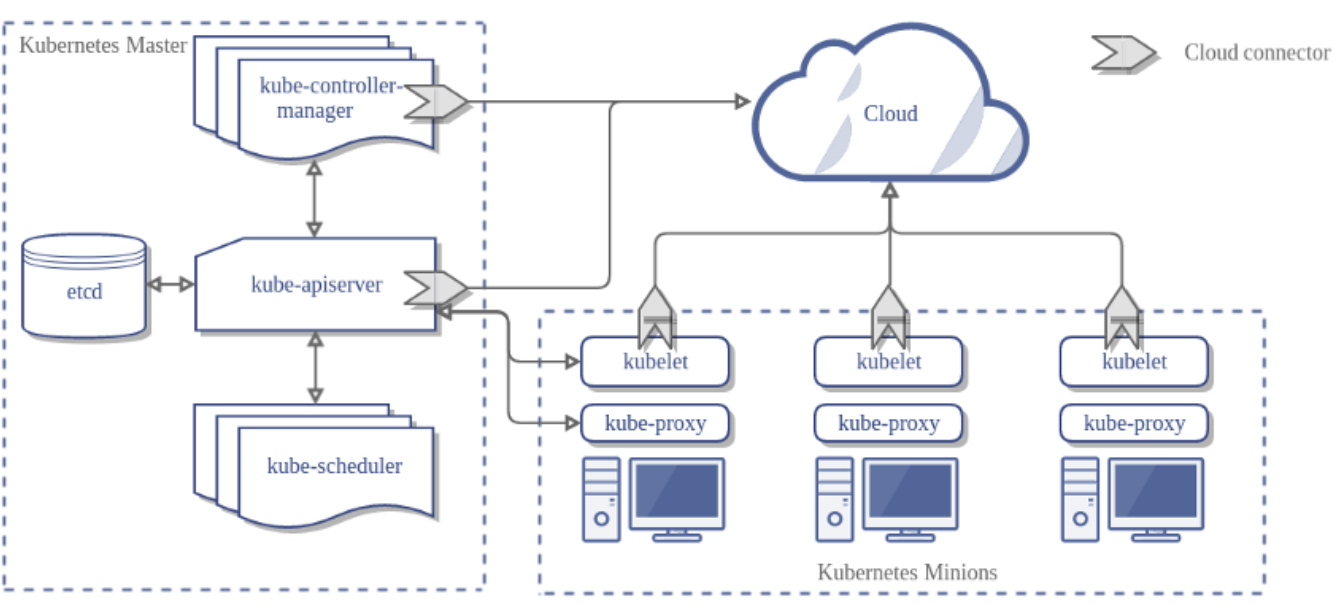
从这张架构图中,我们能看到 Kubernetes 主要由控制平面(Control Plane)和工作节点(Worker Nodes)两大部分构成,它们相互协作,宛如一部精密运转的机器。接下来,咱们就逐一深入了解那些核心组件。
二、控制平面组件:幕后的智慧大脑
(一)API 服务器(API Server):工厂的 “总经理”
API 服务器堪称 Kubernetes 集群的 “大管家”,如同工厂里的总经理,掌管着所有请求的 “生杀大权”。它对外提供了 RESTful API 接口,不管是咱们开发者通过kubectl下达的指令,还是其他组件之间的交互请求,都得经过它的 “法眼”。它就像一个信息中枢,接收、验证并处理各种对集群资源的操作请求,然后将处理结果反馈给请求方。比如,当我们想要创建一个新的 Pod 时,这个创建请求首先就会被 API 服务器捕获,它会仔细检查请求的格式是否正确、权限是否足够等,只有一切合规,才会继续后续的处理流程。
(二)etcd:集群的 “超级记事本”
etcd 扮演着集群中 “超级记事本” 的角色,它是一个高可用的键值对存储系统,专门用来记录集群的所有配置信息和状态信息。你可以把它想象成一个超级可靠的账本,里面详细记录着每个 Pod 的定义、状态,以及各种资源的分配情况等重要信息。API 服务器需要读取或修改这些信息时,都会找 etcd “对账”。而且,etcd 的设计非常巧妙,它具备强大的容错能力,就像有多个备份账本一样,即使部分节点出现故障,也能确保数据的完整性和一致性,保证整个集群不会因为信息丢失而陷入混乱。例如,当一个新的 Node 节点加入集群时,其相关信息就会被准确无误地记录到 etcd 中,以便其他组件随时查询使用。
(三)控制器管理器(Controller Manager):精明的 “调度主管”
控制器管理器就像是工厂里精明的调度主管,时刻监控着整个集群的运行状态,确保一切都按计划有条不紊地进行。它包含了众多不同类型的控制器,每种控制器都专注于特定资源的管理。比如,副本控制器(Replication Controller)负责保证指定数量的 Pod 副本始终处于运行状态,如果实际运行的 Pod 数量少于我们设定的副本数,它就会立刻着手创建新的 Pod;而节点控制器(Node Controller)则密切关注着每个 Node 节点的健康状况,一旦发现某个节点出现故障,它会迅速采取行动,比如将该节点上的 Pod 重新调度到其他健康节点上,以保障服务的连续性。可以说,控制器管理器就是集群稳定运行的 “定海神针”。
(四)调度器(Scheduler):聪慧的 “资源分配大师”
调度器是 Kubernetes 中的 “资源分配大师”,它的职责是为新创建的 Pod 找到最合适的 Node 节点来运行。这可不是一件简单的事情哦,它需要综合考虑众多因素,比如每个 Node 节点的资源使用情况(CPU、内存、磁盘空间等)、节点的负载均衡、Pod 对资源的需求以及一些特定的亲和性或反亲和性规则等。就好比一个聪慧的人力资源主管,要根据每个员工的技能、工作负荷以及项目需求,将新任务合理分配给最合适的员工。例如,当一个对 CPU 资源要求较高的 Pod 被创建时,调度器会在众多 Node 节点中筛选出那些 CPU 资源相对充裕的节点,然后再结合其他条件,最终确定一个最优的节点来运行这个 Pod,从而实现集群资源的高效利用。
三、工作节点组件:一线的 “实干家”
(一)kubelet:节点的 “大管家”
在每个工作节点上,kubelet 就像是这个节点的 “大管家”,负责与控制平面进行通信,管理该节点上 Pod 的生命周期。它时刻监听着 API 服务器的指令,一旦收到创建、更新或删除 Pod 的任务,就会立即付诸行动。它会根据 Pod 的定义,拉取所需的容器镜像,创建并启动容器,同时持续监控这些容器的运行状态,并定期向 API 服务器汇报。如果容器出现故障,kubelet 会根据预设的重启策略决定是否重启容器。比如,当一个 Pod 被调度到某个节点后,kubelet 就会按照 Pod 的配置文件,从镜像仓库中拉取相应的容器镜像,然后在节点上启动容器,让 Pod 顺利运行起来。
(二)kube - proxy:网络的 “智能交通指挥员”
kube - proxy 是集群网络的 “智能交通指挥员”,主要负责为服务提供网络代理和负载均衡功能。在 Kubernetes 集群中,每个服务都有一个虚拟的 IP 地址(Cluster IP),客户端通过这个 Cluster IP 来访问服务。而 kube - proxy 的任务就是将发往 Cluster IP 的请求,智能地转发到后端实际提供服务的 Pod 上。它就像一个繁忙路口的交通指挥员,根据一定的负载均衡算法,将流量合理分配到各个 Pod,确保每个 Pod 都能 “公平” 地处理请求,避免某个 Pod 因流量过大而不堪重负,同时也提高了服务的整体可用性和性能。例如,当一个用户通过服务的 Cluster IP 发送请求时,kube - proxy 会根据预设的负载均衡策略(如轮询、最少连接数等),选择一个合适的后端 Pod 来处理这个请求,让用户的请求能够快速得到响应。
(三)容器运行时(Container Runtime):容器的 “孵化箱”
容器运行时是真正运行容器的环境,常见的有 Docker、 containerd 等,它就像是容器的 “孵化箱”。当 kubelet 需要启动一个容器时,就会与容器运行时进行交互,由容器运行时负责创建和管理容器的生命周期。它会根据容器镜像的定义,在节点上创建一个隔离的容器环境,包括设置容器的文件系统、网络配置、进程空间等。可以说,容器运行时是将容器镜像转化为实际运行容器的关键环节,没有它,容器就无法在节点上 “落地生根” 并正常运行。例如,当 kubelet 从镜像仓库拉取到一个 Docker 镜像后,就会调用 Docker 容器运行时,按照镜像的配置在节点上启动一个容器实例,让应用程序能够在这个容器中欢快地 “奔跑”。
四、Pod 的奇幻生命周期之旅
Pod 作为 Kubernetes 中最小的可部署和可管理单元,它的生命周期充满了奇妙的变化。现在,咱们就以一个简单的 Web 应用 Pod 为例,来看看它在 Kubernetes 集群中的完整生命周期。
(一)创建阶段:梦想起航
当我们通过kubectl命令或者 Kubernetes API 提交一个创建 Pod 的请求后,这个 Pod 的奇妙之旅就正式开启啦。首先,它会进入 Pending(等待)状态。在这个阶段,调度器开始发挥它的 “资源分配大师” 技能,在众多 Node 节点中为这个 Pod 寻觅一个最佳的 “落脚点”。它会综合考量各个节点的资源使用情况、网络状况以及 Pod 自身的资源需求和亲和性规则等因素。比如说,我们这个 Web 应用 Pod 对 CPU 和内存有一定的要求,调度器就会筛选出那些资源充裕且符合亲和性条件的节点。一旦找到合适的节点,调度器就会将这个 Pod “绑定” 到该节点上,此时 Pod 的状态就会从 Pending 转变为 ContainerCreating(容器创建中)。
(二)运行阶段:活力绽放
一旦 Pod 被调度到目标节点,kubelet 这位节点 “大管家” 就开始忙碌起来。它会根据 Pod 的定义,从镜像仓库中拉取所需的容器镜像。假设我们的 Web 应用 Pod 使用的是一个基于 Nginx 的镜像,kubelet 就会努力将这个镜像下载到节点上。镜像拉取完成后,kubelet 会借助容器运行时(如 Docker)创建并启动容器。在容器启动过程中,可能还会涉及到一些初始化操作,比如设置环境变量、挂载存储卷等。当所有容器都成功启动并运行起来后,Pod 就进入了 Running(运行中)状态。此时,我们的 Web 应用就像一艘扬帆起航的船只,开始对外提供服务啦。而且,在 Pod 运行期间,kubelet 会持续监控容器的运行状态,定期执行健康检查,确保一切正常。如果健康检查发现容器出现异常,比如 Nginx 服务停止响应,kubelet 会根据预设的重启策略决定是否重启容器,以保证 Web 应用的持续可用。
(三)终止阶段:优雅谢幕
当我们不再需要这个 Pod 时,比如要对 Web 应用进行升级或者资源进行重新调配,就会下达删除 Pod 的指令。此时,Pod 进入终止阶段。首先,API 服务器会将 Pod 的状态标记为 Terminating(终止中),并通知相关组件。kubelet 收到通知后,会先给容器发送一个停止信号(通常是 SIGTERM 信号),让容器有机会进行一些优雅的关闭操作,比如保存未完成的数据、关闭网络连接等。这个过程有一个默认的宽限期(通常是 30 秒),我们也可以根据实际业务需求进行自定义。在宽限期内,如果容器成功停止,kubelet 会进一步清理容器相关的资源,如删除容器实例、清理存储卷等。当所有清理工作完成后,Pod 就会彻底从集群中消失,完成它的整个生命周期,就像一场精彩演出落下帷幕。
五、Deployment 管理 Pod 的精彩历程
Deployment 是 Kubernetes 中用于管理无状态应用的强大工具,它就像是 Pod 的 “智能指挥官”,能够轻松实现应用的部署、升级、回滚等操作。接下来,我们以一个简单的示例来看看 Deployment 是如何管理 Pod 的生命周期的。
假设我们有一个名为my - web - app的 Web 应用,最初版本是 v1。我们使用 Deployment 来管理这个应用的 Pod。
(一)初始部署:搭建舞台
我们通过编写一个 Deployment 的配置文件(如下所示),并使用kubectl apply -f命令提交给 Kubernetes 集群。
apiVersion: apps/v1
kind: Deployment
metadata:
name: my - web - app - deployment
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: my - web - app
version: v1
template:
metadata:
labels:
app: my - web - app
version: v1
spec:
containers:
- name: my - web - app - container
image: my - web - app:v1
ports:
- name: http
containerPort: 80在这个配置文件中,我们指定了要创建 3 个副本的 Pod,每个 Pod 运行my - web - app:v1镜像,并且通过标签选择器(matchLabels)来标识这些 Pod。当 Kubernetes 收到这个配置后,Deployment 控制器就开始工作啦。它会根据配置创建 3 个符合要求的 Pod,调度器将这些 Pod 分配到合适的 Node 节点上,然后 kubelet 在各个节点上创建并启动容器,就像为这场 Web 应用的 “演出” 搭建好了舞台,3 个 Pod 副本开始协同工作,对外提供稳定的 Web 服务。
(二)版本升级:精彩升级
随着业务的发展,我们对 Web 应用进行了升级,发布了 v2 版本。此时,我们只需要修改 Deployment 的配置文件,将镜像版本更新为my - web - app:v2,然后再次使用kubectl apply -f命令提交。
apiVersion: apps/v1
kind: Deployment
metadata:
name: my - web - app - deployment
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: my - web - app
template:
metadata:
labels:
app: my - web - app
version: v2
spec:
containers:
- name: my - web - app - container
image: my - web - app:v2
ports:
- name: http
containerPort: 80Deployment 控制器检测到配置的变化后,会启动一个滚动升级的过程。它不会一下子将所有 v1 版本的 Pod 全部替换掉,而是采用一种逐步替换的策略。通常情况下,它会先创建一个新的 v2 版本的 Pod,等这个新 Pod 成功运行并通过健康检查后,才会逐渐删除一个旧的 v1 版本的 Pod。这样一来,在升级过程中,Web 应用始终能够对外提供服务,用户几乎不会察觉到服务的中断。就像一场精彩的演出,在不影响观众体验的情况下,顺利完成了演员和剧情的更新。
(三)回滚操作:紧急救援
然而,有时候升级可能会出现问题,比如新的 v2 版本存在严重的漏洞,导致 Web 应用无法正常工作。这时,Deployment 的回滚功能就派上用场啦。我们可以使用kubectl rollout undo命令,Deployment 控制器会迅速将应用回滚到上一个稳定的版本(在这个例子中就是 v1 版本)。它会再次调整 Pod 的副本数量,逐步删除 v2 版本的 Pod,创建并启动 v1 版本的 Pod,直到 Web 应用恢复到升级前的正常状态,就像一场紧急救援行动,迅速让演出回到正轨,保障用户的正常使用。
通过以上对 Kubernetes 核心组件架构的深入剖析,以及 Pod 和 Deployment 生命周期的详细介绍,相信你已经对 Kubernetes 这个云原生世界的 “魔法大师” 有了更深刻的理解。这些组件相互协作、紧密配合,为我们构建了一个高效、稳定且易于管理的容器编排平台,让现代应用的部署与运维变得更加轻松和强大。
评论