
今天分享一个在项目中遇到的bug,这个bug导致线上服务经常异常性流量阻塞加OOM。
同时分享一下我们的开源项目:https://github.com/alipay/container-observability-service
1.前言
首先,介绍一下项目情况,便于对后续内容有一定认知基础。
1. 基本架构
我们的项目是对 k8s 的各类基础资源和扩展性资源作可观测性诊断的,基本架构如下:
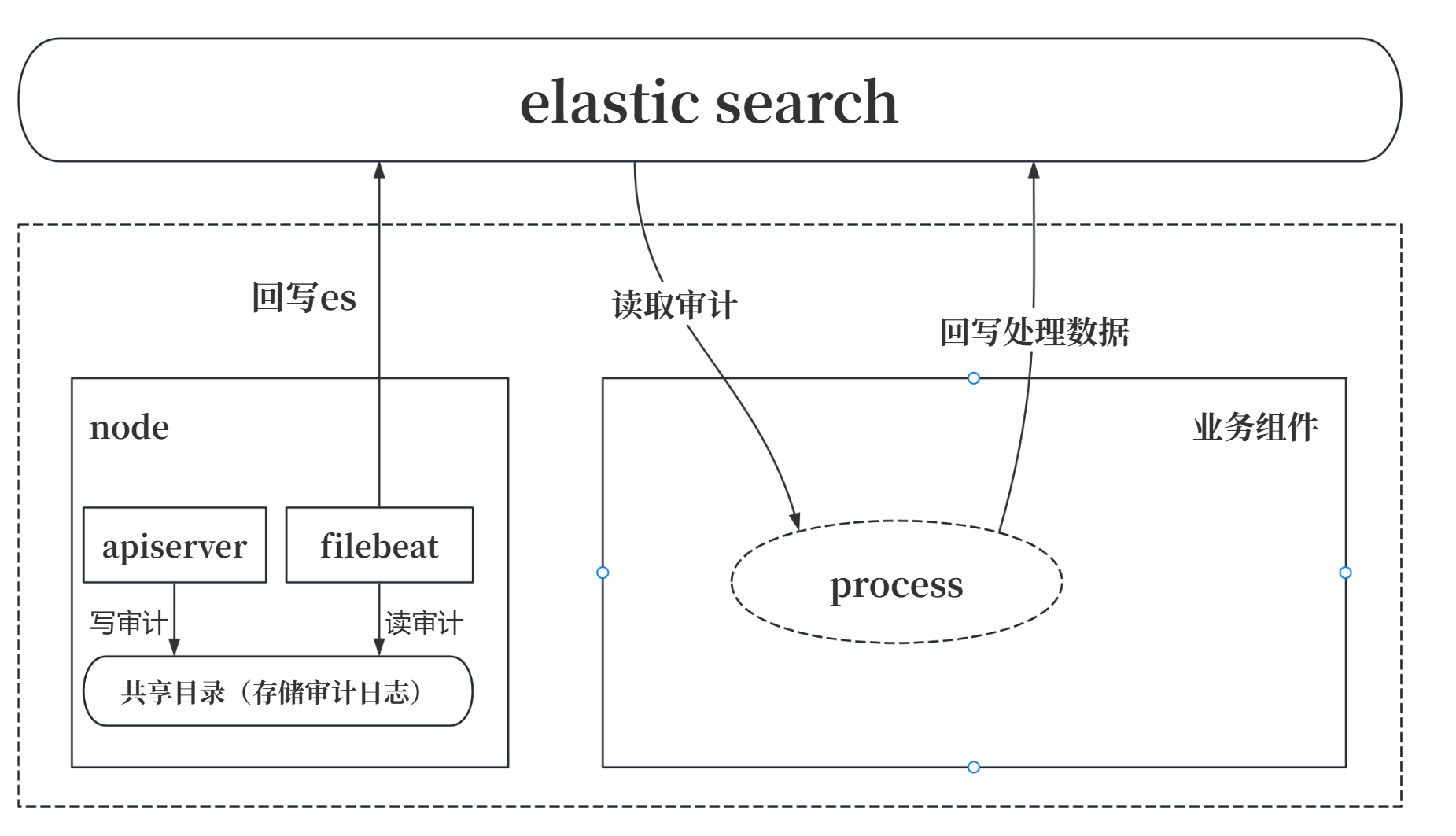
apiserver 记录所有资源的操作审计日志,将审计日志输出到共享目录。
filebeat 通过daemonset结合亲和性标签,与apiserver部署同一节点,采集共享目录的审计数据,回写elasticserach。
后端处理组件读取elasticsearch审计数据,进行一系列处理之后,回写处理后的数据。
2. process核心依赖
process的核心依赖如下:
伪代码:
// 从es读取事件
type Event struct {
canProcess bool
notify chan struct{}
}
func (e *Event) Notify() {
e.canProcess = true
e.notify <- struct{}{}
}
type Queue1 struct {
msg chan interface{}
}
func (q *Queue1) Produce(msg interface{}) {
q.msg <- msg
}
func (q *Queue1) Consume() {
go func() {
for eventItf := range q.msg {
event := eventItf.(*Event)
for {
if event.canProcess {
break
}
<-event.notify
}
// 消费
}
}()
}
type Queue2 struct {
msg chan interface{}
batchQueue []*Event
}
func (q *Queue2) Produce(msg interface{}) {
q.msg <- msg
}
func (q *Queue2) Consume() {
go func() {
for eventItf := range q.msg {
event := eventItf.(*Event)
// 某个不满足条件的情况下,q2队列不处理,结束任务,通知q1处理
if condition1 {
event.Notify()
continue
}
// 满足条件的情况下,q2 进行批处理, 假设满100个处理
q.batchQueue = append(q.batchQueue, event)
if len(q.batchQueue) == cap(q.batchQueue) {
for _, event := range q.batchQueue {
// 经过一系列处理
// 然后结束任务,通知q1处理
event.Notify()
}
q.batchQueue = q.batchQueue[:0]
}
}
}()
}
var (
queue1 = &Queue1{
msg: make(chan interface{}, 200000),
}
queue2 = &Queue2{
msg: make(chan interface{}, 200000),
batchQueue: make([]*Event, 0, 100),
}
)
func readMsg() {
// 模拟从es读取解析到的一个事件
read := func() *Event {
return &Event{
canProcess: false,
notify: make(chan struct{}, 1),
}
}
for {
event := read()
wg := sync.WaitGroup{}
wg.Add(1)
go func() {
queue1.Produce(event)
queue2.Produce(event)
}()
wg.Wait()
}
}不断向es读取数据,进行消费,将数据同步写入队列1和队列2。
队列1在进行消费时,依赖队列2消费结束调用Notify()。
队列2的消费有两种可能:
不满足消费条件:则队列2不处理,调用Notify()之后,不阻塞队列1处理。
满足消费条件:进行批处理,事件塞入批处理队列,队列满后进行处理。
由于逻辑设计,事件的消费需要有序,不能多线程消费。
2.问题
我们的可观测能力作为集团内部的基础架构能力,服务于集团上层几乎所有业务,数据量及其庞大。秒级审计日志达数十万条。
业务组件在线上运行时,时常发生OOM,或者突然之间不消费数据了,形成数据阻塞情况。
问题难点:
线上事件量大,组件要么快速OOM,要么需要快速重启恢复消费,无法保留现场。
无法采集pprof,进行阻塞分析。
上下文过多,阻塞点无法分析。(1.2.涉及的核心依赖,是从一堆代码抽离出来的伪代码,实际代码及其复杂😭)
3.debug
定位手段:
基于2中描述的问题,核心在于无法捕捉问题现场。
基于此问题,我才用了流量回放的手段,进行定位。
开启metrics监控。(业务组件对各队列有埋点监控)
私有环境部署业务。
同步问题发生点前后1小时数据,不断在私有环境作问题回放。
切入点:
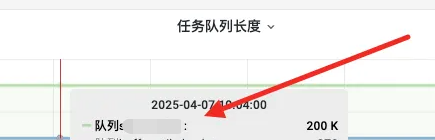
发现了问题点,都是队列1满了。
4.原因分析
回到1.2.中的代码:存在死锁可能。
当事件1,进入queue2,可以被处理,但是queue2的batchsize没满,不处理。
接下来不断来了20w个数据,这些数据都不满足queue2的处理条件,于是queue2不处理。
这20w个数据,由于事件1在queue2还没处理,所以在queue1队头阻塞,20w个事件打满了queue1队列。
由于queue1满,所以readMsg,无法写入事件到queue1,整体阻塞。
5.解决方案
由于依赖里面对于batchqueue是定量处理的,batchQueue满了才处理,所以存在死锁。
可以增加延时处理,或增加queue1队列的反向通知。修改如下:
func (q *Queue2) Consume() {
go func() {
for eventItf := range q.msg {
event := eventItf.(*Event)
// 某个不满足条件的情况下,q2队列不处理,结束任务,通知q1处理
if condition1 {
event.Notify()
continue
}
// 满足条件的情况下,q2 进行批处理, 假设满100个处理
q.batchQueue = append(q.batchQueue, event)
if q.canProcess() {
for _, event := range q.batchQueue {
// 经过一系列处理
// 然后结束任务,通知q1处理
event.Notify()
}
}
}
}()
}
func (q *Queue2) canProcess() bool {
return len(q.batchQueue) == cap(q.batchQueue) ||
time.Now().Sub(q.lastProcessTime) >= 5*time.Second
}
评论